
音声にあわせて一枚絵を動かす SadTalker - Stable Diffusion WebUI の拡張機能
1枚の顔写真と音声データを組み合わせて、その音声をしゃべっているかのように顔を動かせる SadTalker を使ってみます。これは単独のアプリケーションでもありますが、Stable Diffusion の WebUI に拡張機能として使うことが可能なので、この方法で使ってみます。
準備
Docker コンテナを起動します。
>$ docker run -it --gpus=all --rm -p 7860:7860 -v /home/tadashi/work:/work nvidia/cuda:11.8.0-base-ubuntu22.04 /bin/bashapt で必要なパッケージをインストールします。
># apt update
># apt install -y git python3-venv libgl1-mesa-dev libglib2.0-0 ffmpeg wgetgit で WebUI をダウンロードします。また、コンテナの中だと root ユーザーになってしまい、WebUI の起動がブロックされるので、それを回避します。
># git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
># cd stable-diffusion-webui/
># sed -i -e s/can_run_as_root=0/can_run_as_root=1/ webui.shSadTalker 拡張機能のインストール
WebUI を起動します。外部の拡張の読み込みを有効にするためのオプションも追加する必要があります。
># COMMANDLINE_ARGS="--listen --enable-insecure-extension-access" ./webui.shpip などで環境構築が走るので、場合によっては 10 分程度待つと、以下のように URL が表示されるので、ブラウザでアクセスします。
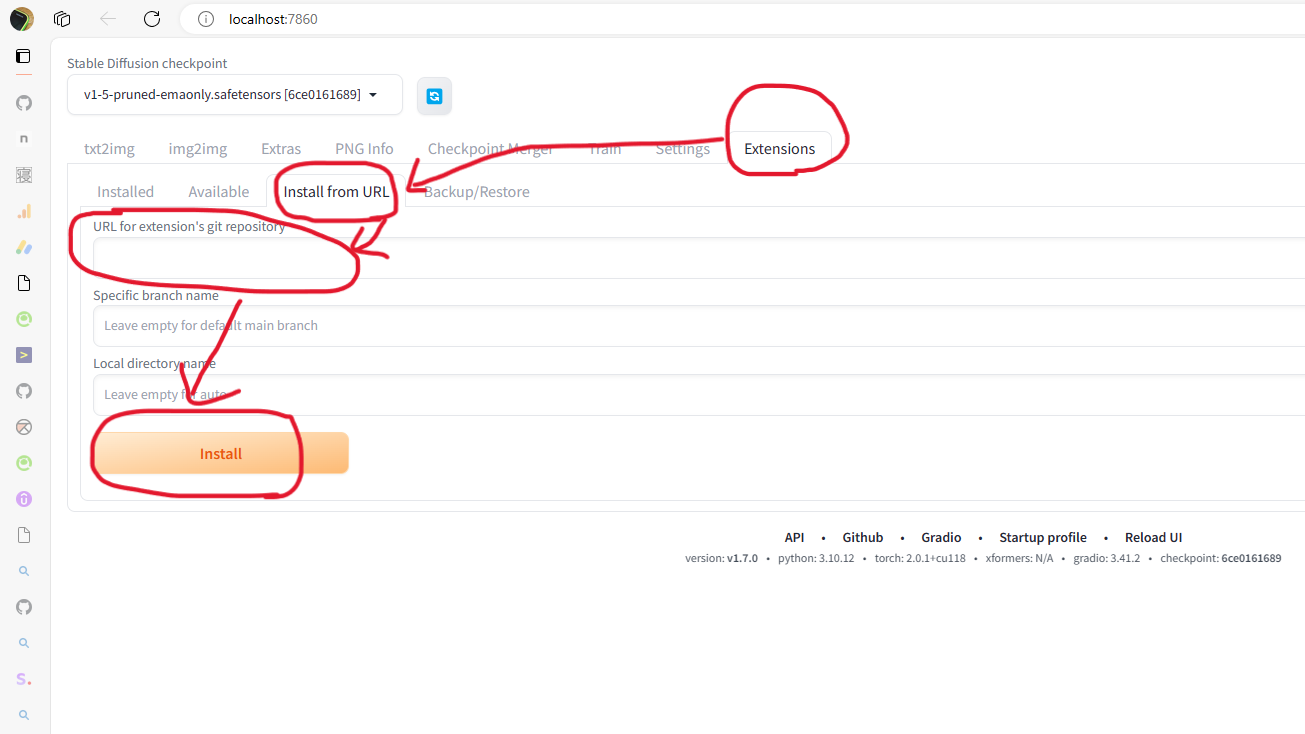
「Extension」>「Install from URL」を選択し、「URL for extension’s git repository」欄にhttps://github.com/OpenTalker/SadTalker.gitと入力して「Install」をクリックします。
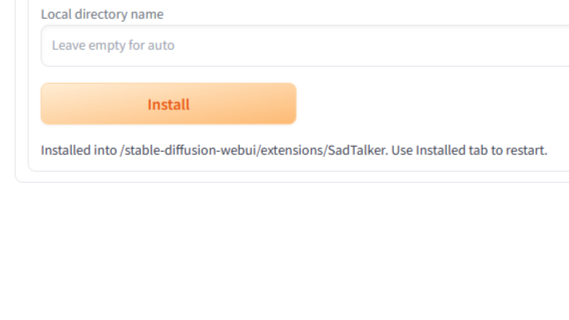
少し待って Install ボタンの下にInstalled into /stable-diffusion-webui/extensions/SadTalker. ~と表示されることを確認し、いったんターミナルから Ctrl+c を押して webui.sh を停止します。
SadTaker のモデルをダウンロードします。上記で表示された、SadTalker をインストールしたディレクトリへ移動して、ダウンロード用のコマンドを実行します。
># pushd extensions/SadTalker/
># bash scripts/download_models.sh
># popd動画の生成
再度 WebUI を起動します。SadTalker が有効化されるので、ここの起動も少し時間がかかります。
># COMMANDLINE_ARGS="--listen --enable-insecure-extension-access" ./webui.sh「SadTalker」タブができているので、これをクリックします。
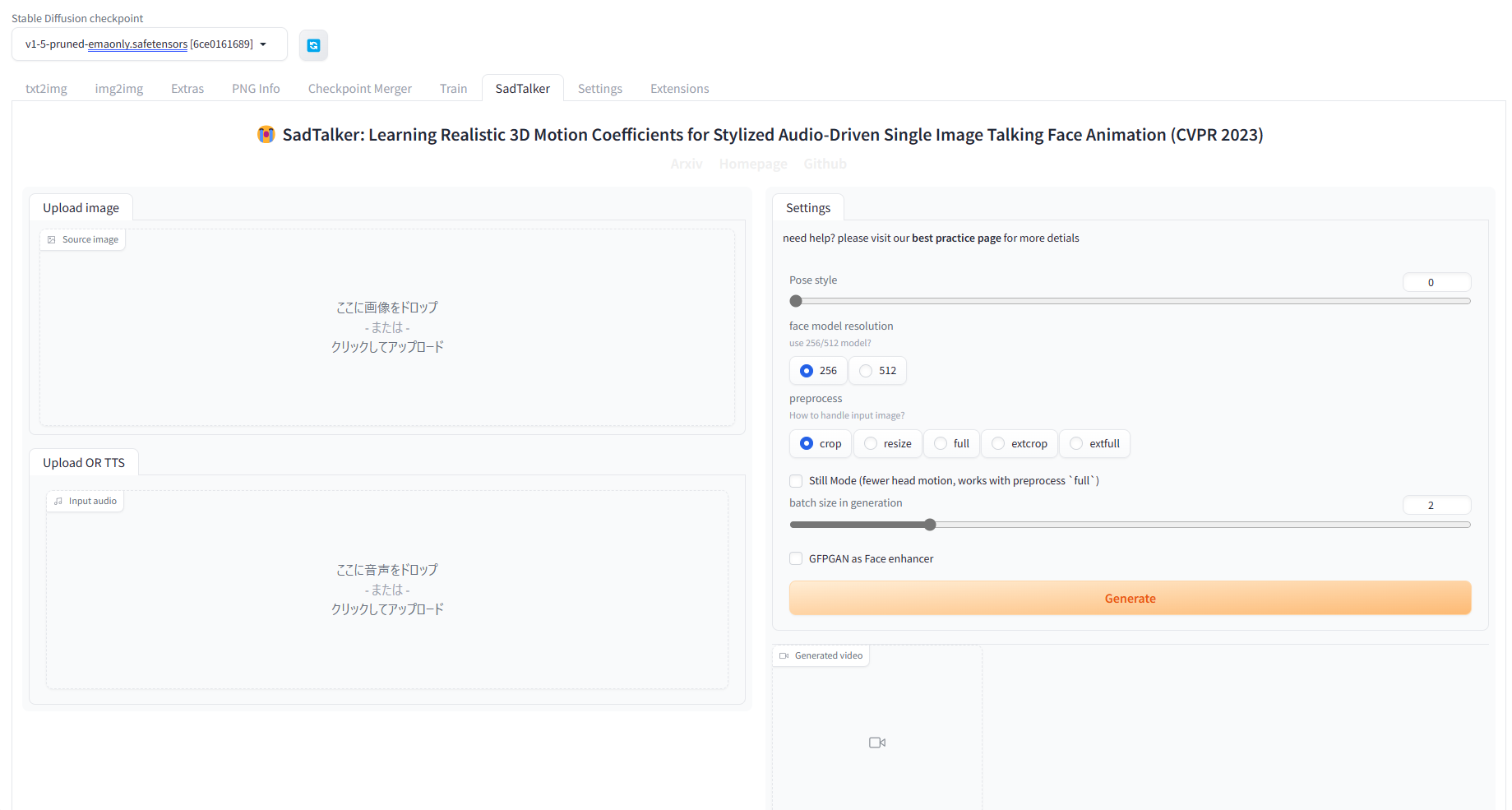
Source imageに画像ファイルを、Input audioに音声ファイルを指定し、Generateをクリックすると、動画が生成されます。
30秒弱の音声データを使った場合、GeForce RTX 2070 でも約2分程度で動画が生成されました。