
Stable Diffusion 3 を試してみた
最も洗練された画像生成モデル、Stable Diffusion 3 Medium のオープンリリースを発表
Stable Diffusion 3 のモデルがリリースされたようなので、試してみます。なお、現在は非商用利用のみ可能なライセンスのようです。
準備
GPU を使えるように設定済みのコンテナを使います。
docker run -it --gpus=all --rm -v /home/tadashi/work:/work nvcr.io/nvidia/cuda:12.1.0-base-ubuntu22.04 /bin/bash必要なパッケージをインストールします。
apt update
apt install -y git python3-pip libgl1-mesa-dev libglib2.0-0pip で pytorch をインストールします。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121Huggin Face のモデルダウンロードページ を開き、モデルの使用に同意します。あわせて Hugging Face のアカウントのトークンも取得します。
モデルのページに記載の通り、diffusers をインストールします。サンプルの実行には transformers も必要なので、あわせてインストールします。
pip install -U diffusers transformers[sentencepiece]※補足:transformers をインストールしただけだと、以下のエラーが発生しました。
ValueError: Cannot instantiate this tokenizer from a slow version. If it's based on sentencepiece, make sure you have sentencepiece installed.
これを解決するために、sentencepiece をあわせてインストールするようにしています。
実行
モデルのページにあるコードを実行してみます。初回実行時はモデルをダウンロードするので、20GB 程のダウンロードが発生します。
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
image = pipe(
"A cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
).images[0]
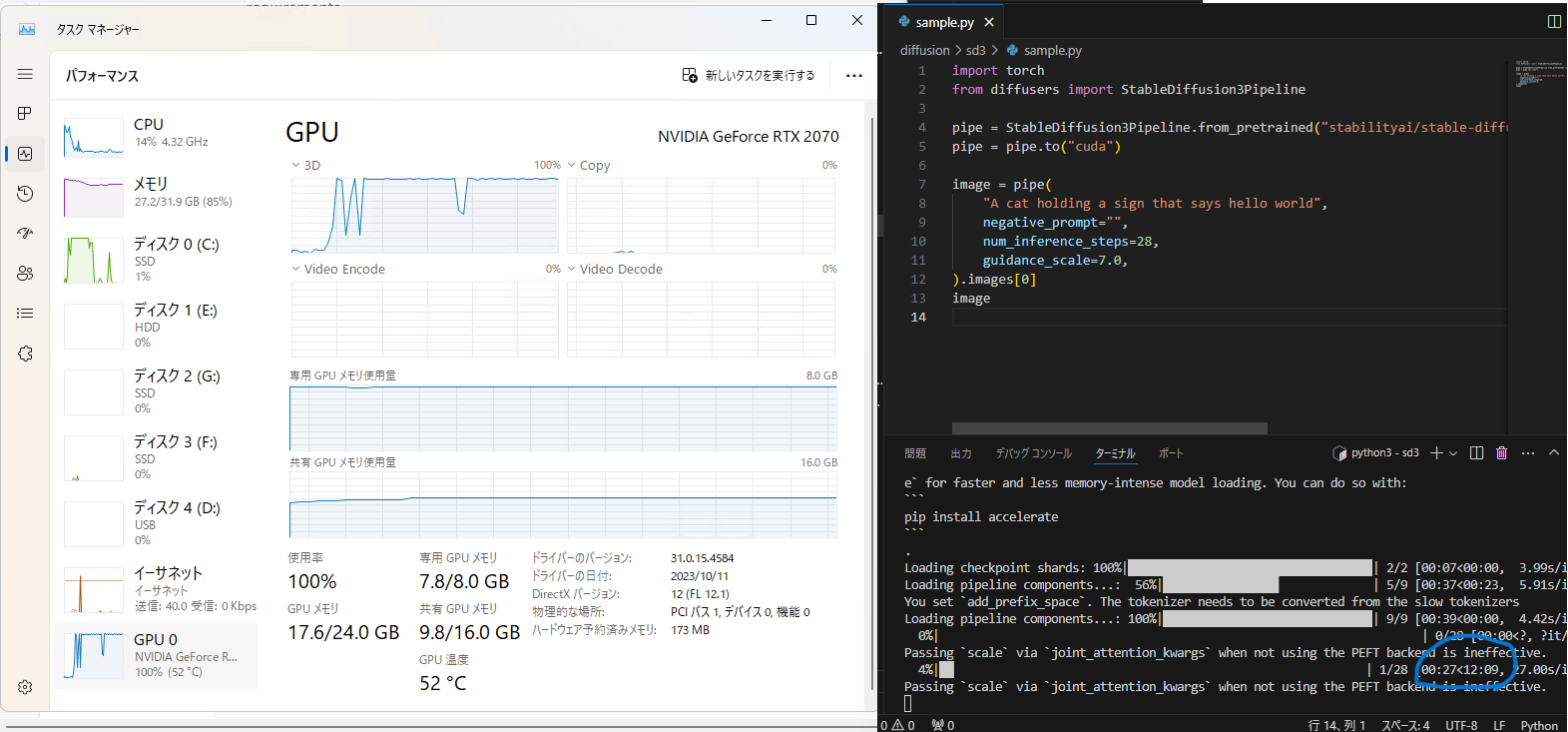
imageGPU をガンガン使っているのが見えます。なお、右下に青丸で囲んだ通り、1 枚生成するのに手元の環境では 12 分以上かかります。
Hello World! 文字もきれいに出力されていますね。
