
Stable Audio Open 1.0 を ComfyUI で使ってみる
少し前になりますが、Stable Audio Open 1.0 がリリース されてました。これを ComfyUI で実行してみました。
ComfyUI 環境準備
Stable Diffusion 3 Medium を実行する環境を ComfyUI で用意した手順 を実行し、コンテナで ComfyUI を実行できるようにします。
Stable Audio Open 1.0 の準備
引き続き、追加のパッケージをインストールします。まずは apt で cuda-toolkit-12-1 と libsndfile1 をインストールします。
apt install -y cuda-toolkit-12-1 libsndfile1次に pip で stable-audio-tools をインストールします。
pip install stable-audio-toolsHugging Face のモデルのページ から、以下のファイルをダウンロードして、ComfyUI の models/audio_checkpoints/ ディレクトリに配置します。このディレクトリが存在しない場合は、ディレクトリを作成してファイルを配置します。
- model_config.json
- stable-audio-open-1.0_model.safetensors
起動 & Custom Node 導入
ComfyUI のディレクトリで以下コマンドを実行し、起動します。
python3 main.pyブラウザで UI を開いたら、右下の Manager をクリックします。
ComfyUI Manager Menu が開くので、Custom Node Manager をクリックします。
上部の「Search」欄に stableaudio と入力します。すると ComfyUI Stable Audio Open 1.0 Sampler があるので、それをインストールします。
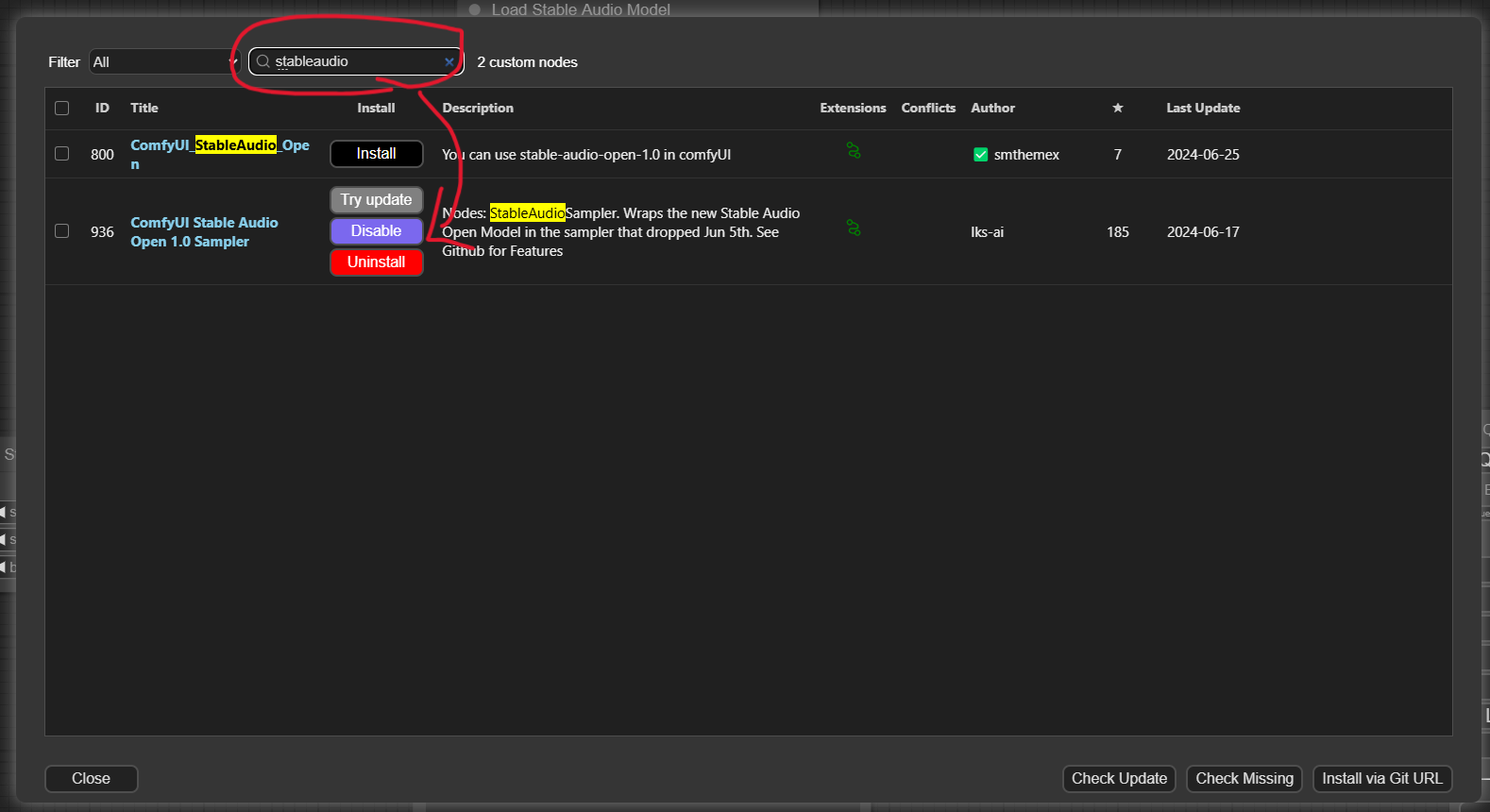
なお、上記画面はすでにインストール済みの画面となっていますが、本来なら「Try update」などのボタンが並んでいる箇所が「Install」になっているので、それをクリックしてインストールします。また、インストール後は ComfyUI の再起動と、ブラウザのリロードが必要になります。
生成
Custom Node が導入できたら、以下のようにノードをつなげます。そのうえでメニューの Queue Prompt をクリックすると、10秒ほどで曲が生成されます。
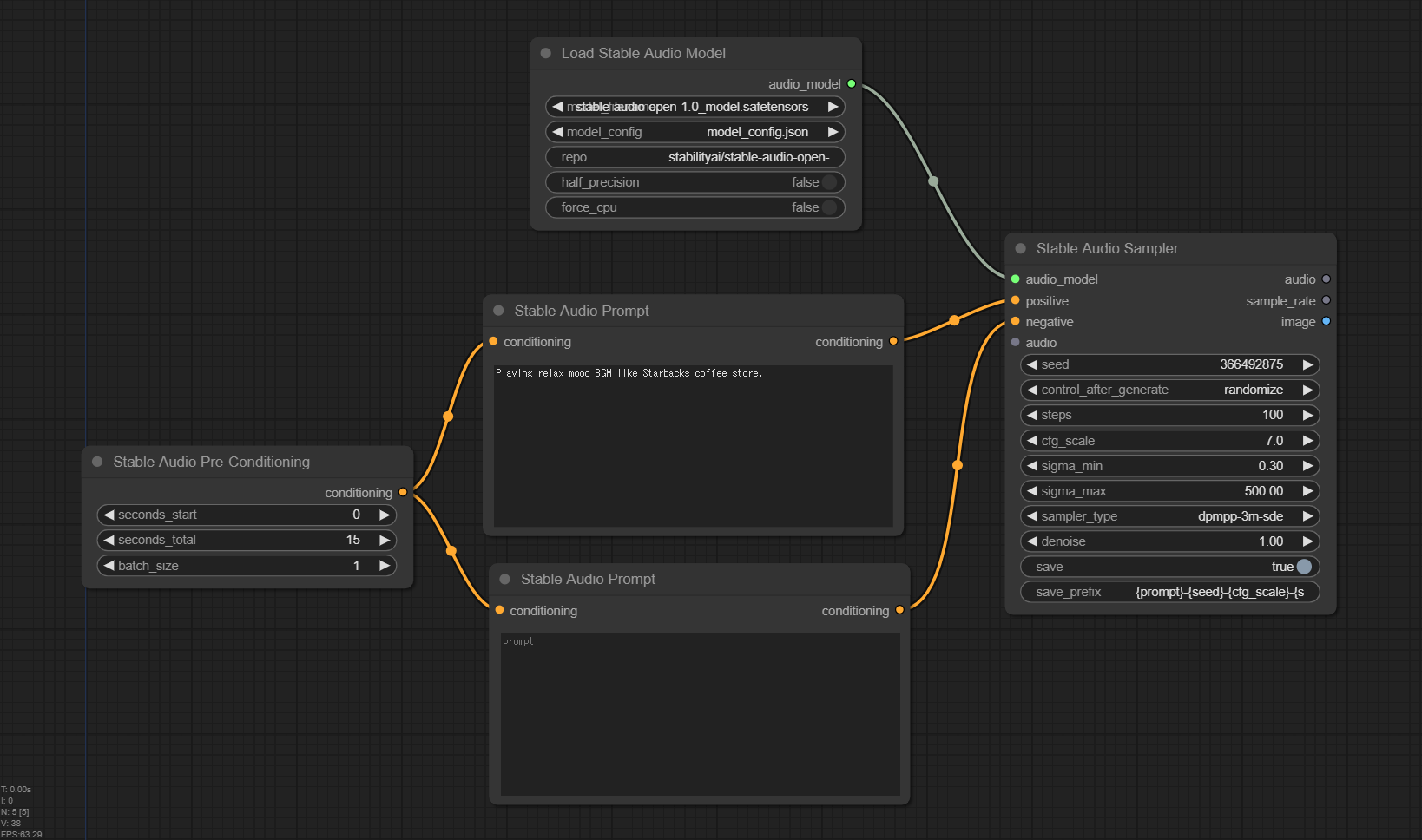
注意点としては以下がありました。
- 「Load Stable Audio Model」ノードで、ダウンロードした
model_config.jsonとstable-audio-open-1.0_model.safetensorsが認識していることを確認します - 「Stable Audio Pre-Conditioning」ノードの
seconds_totalが曲の長さですが、GeForce RTX 2070 (VRAM 8GB) では15 (秒)ぐらいが上限でした。それ以上にすると、CUDAoutofmemory が発生して生成に失敗します - 「Stable Audio Sampler」の
saveをtrueにしておかないと、処理がエラーとなって生成に失敗します - 「Stable Audio Sampler」の
control_afer_generateは初期値がfixedになっており、seed 値が固定です。手動で変更する場合はこれで問題ないのですが、いろいろ試したい場合はここをrandomizeにしておくと、生成後に seed 値をランダムに変更するようになります - 「Stable Audio Sampler」は生成後に音楽を再生してくれます。この後に Preview のノードをつなげなくても確認可能です。ローカルにダウンロードしたい場合は、
ComfyUI/outputディレクトリに出力されたファイルをダウンロードすればよさそうです。