
FLUX.1 [schnell] を試してみる
Stable Diffusion を超えたとも噂される FLUX.1 を試してみました。GeForce RXT 2070 (VRAM 8GB)、メインメモリ 32GB だとギリギリ動く、といった感じです。UI は ComfyUI を使ってみます。
ComfyUI 環境準備 & 起動
Stable Diffusion 3 Medium を実行する環境を ComfyUI で用意した手順 を実行し、コンテナで ComfyUI を実行できるようにします。ComfyUI Manager 以外のカスタムノードを追加する必要はありません。
その後、ComfyUI のディレクトリで以下コマンドを実行し、起動します。
python3 main.pyブラウザで UI を開けることを確認します。
モデルの準備
種類
FLUX.1 には、以下 3 種類のモデルがリリースされました。
- FLUX.1 [pro]
- FLUX.1 [dev]
- FLUX.1 [schnell]
[pro] は API やパートナーサイトでのみ使用できるそうです。[dev] と [schenll] は GitHub や Hugging Face でモデルをダウンロードすることが可能で、ザックリ言えば [schnell] の方が軽量、[dev] は高品質という感じです。ライセンスも違っていて、[schenll] の方が比較的自由に扱えるライセンスになっています。今回は [schnell] を使ってみます。
必要なモデル
FLUX.1 は、テキストエンコーダーや VAE が別配布となっているようです。ただ、それらを組み込んで生成されたモデルも配布されているようなので、その辺はモデルの配布元の情報などを確認する必要があります。今回はオリジナルの FLUX.1 [schnell] を使用したいと思うので、個別にダウンロード、配置をする必要があります。
まずは Hugging Face からダウンロードします。FLUX.1 schnell から、以下のファイルをダウンロードします。
- flux1-schnell.safetensors
- ae.safetensors
flux1-schnell.safetensors は ComfyUI/models/unet/ へ、ae.safetensors は ComfyUI/models/vae/ へ配置します。
テキストエンコーダーも別途必要なのですが、Stable Diffusion 3 Medium を実行する環境を ComfyUI で用意した手順 でダウンロードした Stable Diffusion 3 Medium のテキストエンコーダーが利用できたので、それをそのまま流用します。以下 2 ファイルが ComfyUI/models/clip/ 配下に存在するはずです。
- clip_l.safetensors
- t5xxl_fp8_e4m3fn.safetensors
生成
ComfyUI_example の Flux Examples にワークフローがあります。いつものように、画像をドラッグ&ドロップすると、ワークフローを読み込むことが可能です。
Example は、モデル分割のワークフローと、統合されたワークフロー (Simple to use FP8 Checkpoint version 項) があります。今回使用するモデルは分割版の schnell ですが、dev のワークフローでも steps の値が異なるだけで、処理方法は同じです。
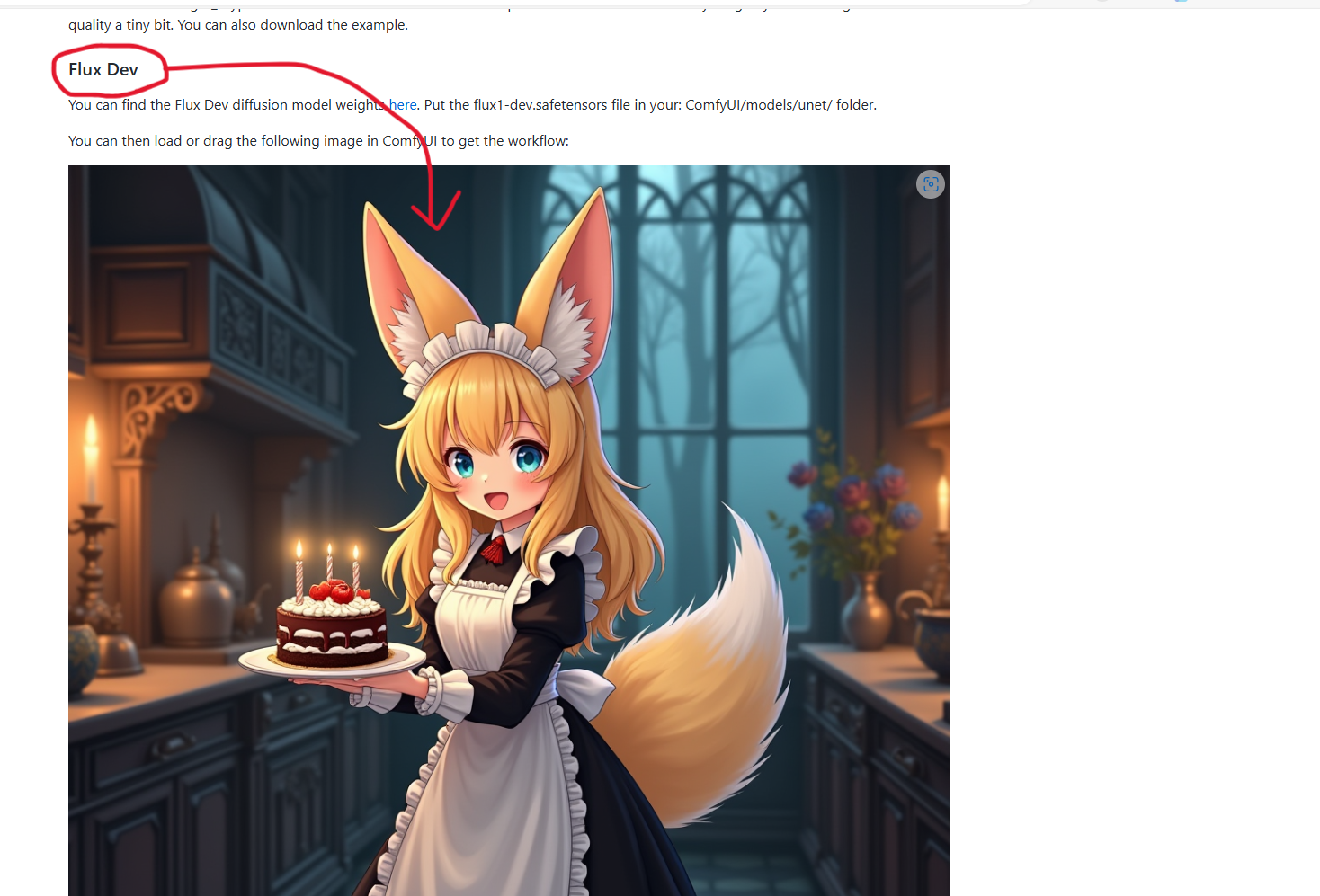
ワークフローを読み込ませたら、Load Diffusion Model の weight_dtype を fp8_e4m3fn に変更しておきます。default のままだとメモリ不足で生成に失敗します。
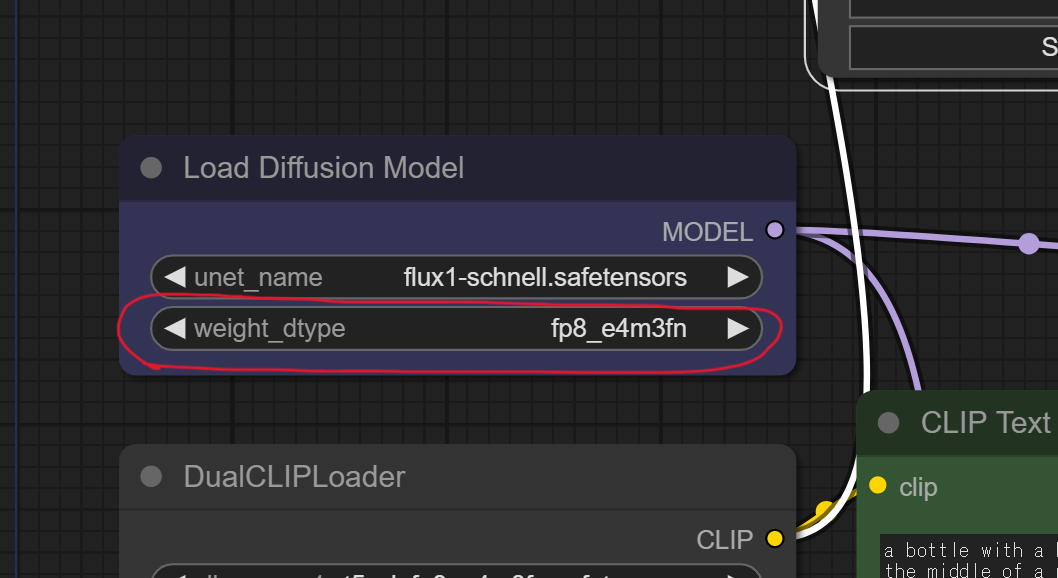
あとはプロンプトを設定して Queue Prompt してみます。以下の通り、1 枚生成するのに 88.03 秒とかかかります。schenll なので 4steps しかしていないはずなのですが、それでも時間がかかります。
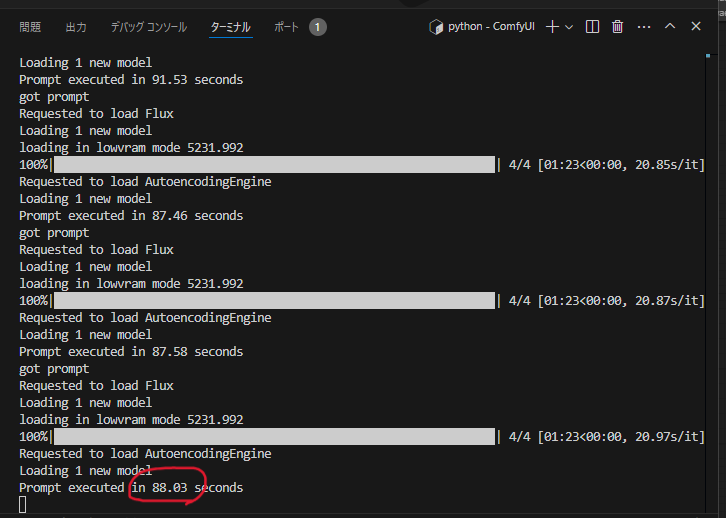
生成される絵はこんな感じ。指も破綻なく生成されることが多い印象です。

FLUX.1 [dev] のモデルも、同様に生成が可能ですが、20 steps でも 1 枚生成するのに 10 分くらいかかります。