
Ollama と OpenWebUI でローカル LLM
ローカルで LLM を動かす際に便利な、OpenWebUI を使ってみます。なお、OpenWebUI はフロントエンドで、バックエンドには Ollama や OpenAI API を使うことができます。
そのため、すでに Ollama を使っていたり、OpenAI API のクレジットを所有していればそれらを活用できるのですが、どちらも持っていません。この場合、Ollama を含む OpenWebUI の Docker イメージを使うことで、セットアップの手間を省けます。
動画も作ってみました。ほとんど待ち時間なのであまり面白みはありませんが・・・
準備
WSL2 の Docker で CUDA する を参考に、GPU を使えるように設定済みのコンテナを使います。
コマンドだと引数をつけ忘れたりするので、Dcker Compose で操作するようにします。以下の内容を記述したファイルを、compose.yml のファイル名で作成します。
services:
openwebui:
image: ghcr.io/open-webui/open-webui:ollama
volumes:
- ./ollama:/root/.ollama
- ./data:/app/backend/data
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
ports:
- "8080:8080"イメージに「ollama」タグをつけることで、ollama も含まれます。また、8080 番ポートを転送することと、GPU を有効にするための設定も記述します。
さらに同じディレクトリに ollama と data というディレクトリを作成しておきます。内容は空で大丈夫です。このディレクトリをコンテナにマウントして、ダウンロードしたモデルや WebUI の設定をコンテナ外に保管するようにします。こうすることで、不要になったらコンテナを削除することが可能になり、かつ再度利用する際にスムーズに作業を再開することが可能になります。
この状態で、以下のディレクトリ構成になっているはずです。
.
|- ollama/
|- data/
-- compose.yml起動
ファイル、ディレクトリの準備ができたら、以下のコマンドを実行します。
docker compose upしばらく待つとターミナルに Application startup complete. と表示され URL が表示されるので、ブラウザで URL にアクセスします。
ログイン画面が表示されますが、初回は何もアカウントがないはずなので、「サインアップ」をクリックします。
アカウント作成画面になりますが、ローカルに保存するだけのアカウントなので、メールアドレスなどは適当で問題ありません。一応、@ がついたメールアドレス形式になっていないと登録できませんが、メールアドレスの確認なども無いので適当に入力して「アカウントを作成」をクリックします。
これで WebUI を開くことができます。
モデルのダウンロード
初期状態だとモデルが無いので、まずはモデルをダウンロードします。UI 左上の「モデルを選択」をクリックし、検索欄に llama3 と入力します。すると、Ollama.com から "llama3" をプル と表示されるので、これをクリックします。
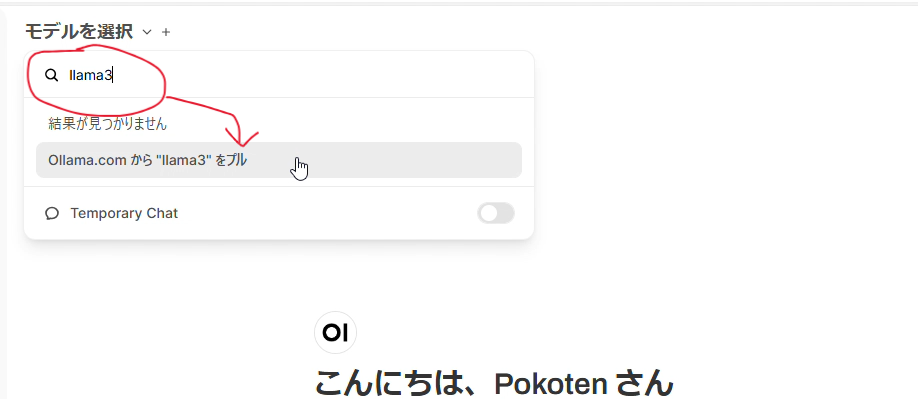
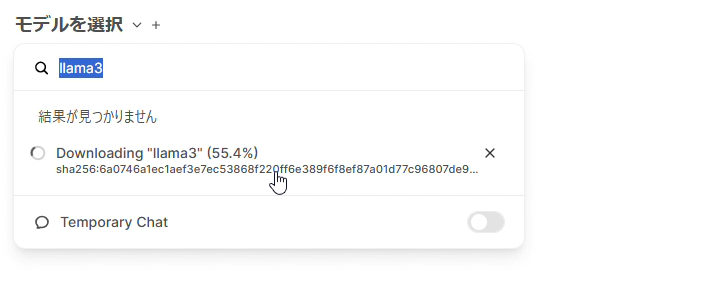
モデルによりますが、数 GB のダウンロードを行うので、それなりの時間がかかります。
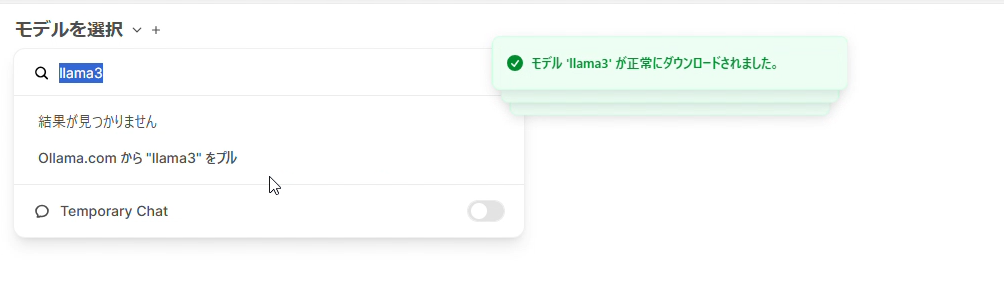
ダウンロードが完了すると、モデル "llama3" が正常にダウンロードされました と表示されます。
今回は llama3 をダウンロードしましたが、他にどんなモデルがあるかは以下のサイトで探すことができます。
生成
モデルのダウンロードが終わったら、「モデルを選択」からダウンロード済みのモデルを選択します。
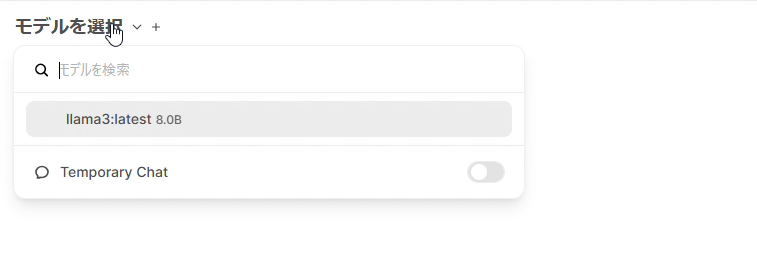
この状態で、チャットが可能になっています。
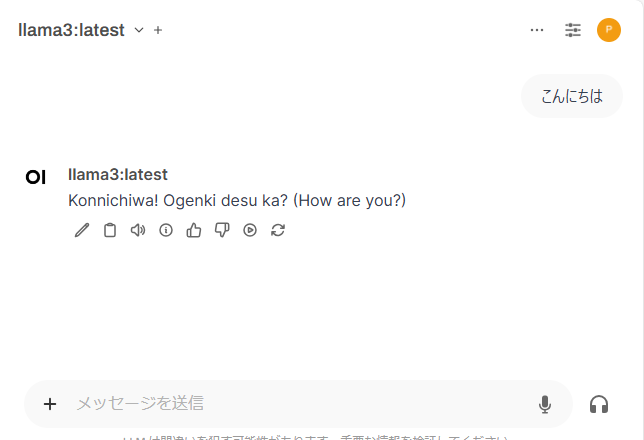
モデル(キャラ付け?)
OpenWebUI の Community ページでも、さまざまなモデルをダウンロードすることが可能です。
なお、こちらは Ollama.com のモデルに対してカスタマイズしたような形のようです。そのため、動作にはベースモデルとして Ollama.com からモデルをダウンロードする必要がありそうです。
なお、同じように自分でカスタマイズすることも可能です。OpenWebUI の「ワークスペース」タブでできそうなのですが、まだそこまで手を付けられていません。