
ComfyUI で CogVideo を試してみる
動画生成モデル CogVideo を試してみます。
概要
- ComfyUI にカスタムノードを追加することで生成できました
- GeForce RTX 2070 (VRAM 8GB) でも生成できました
- 1回生成するのにおよそ 30 分間程度、時々メモリ不足でエラーになることもあります
- Text2Video、Image2Video どちらも生成できました
準備
ComfyUI を docker compose で構築する で用意した docker compose を使います。もしコンテナを起動していない場合は、docker compose start などで起動し、WebUI にアクセスできるようにします。
WebUI を開いたら、右下の Manager をクリックします。
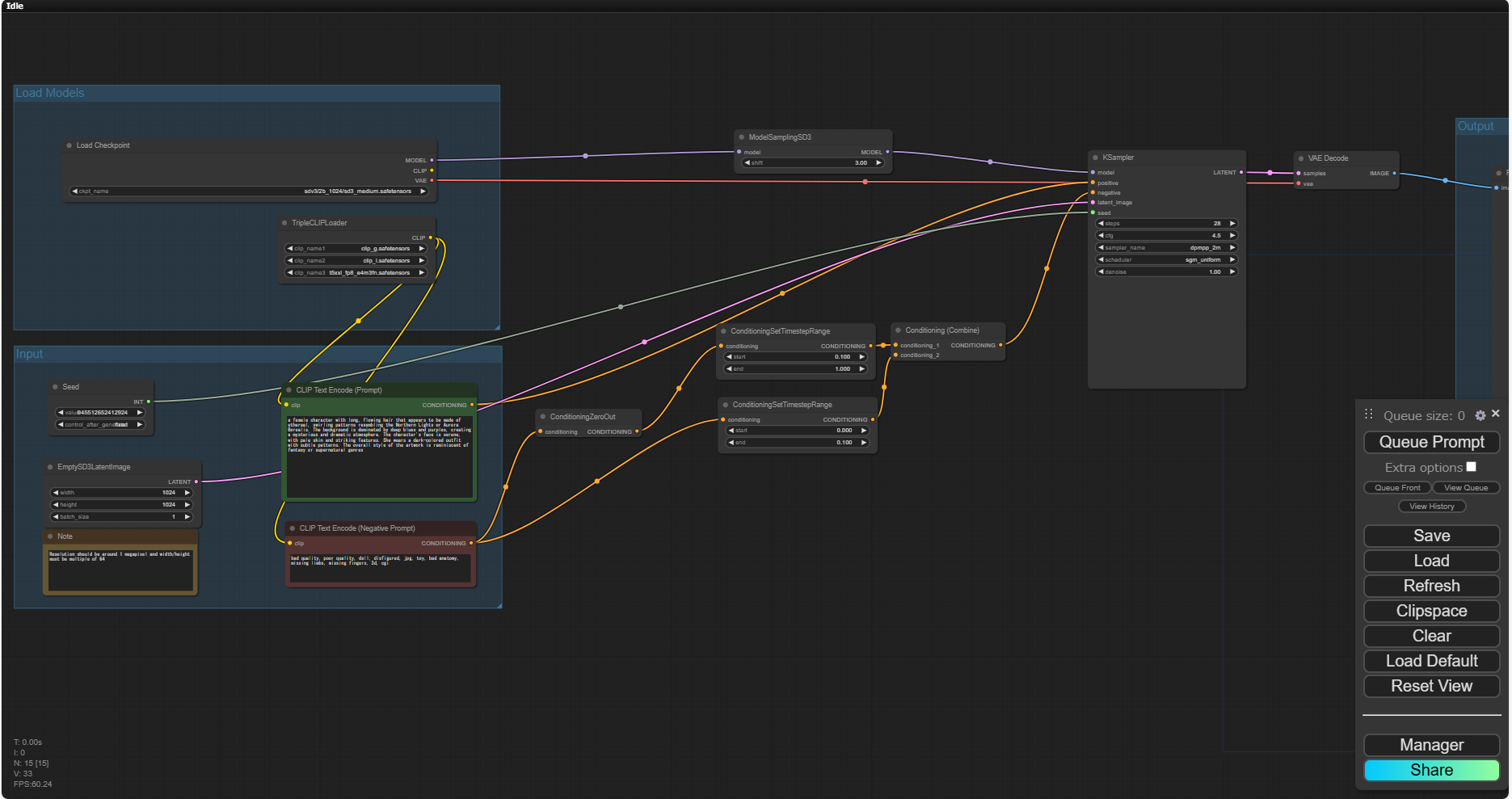
ComfyUI Manager Menu が開くので、Custom Node Manager をクリックします。
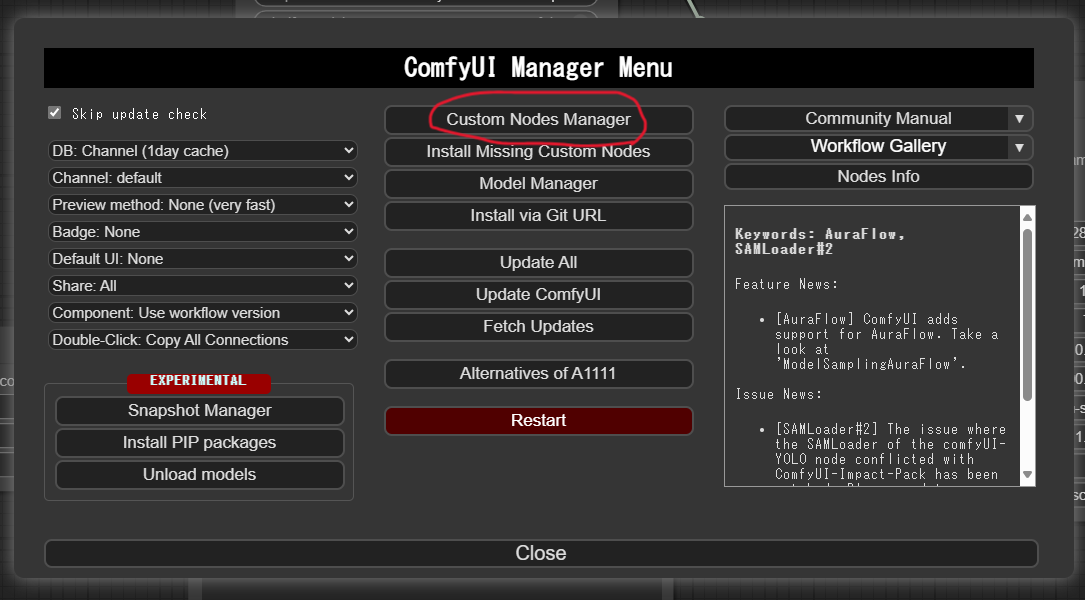
上部の「Search」欄に cogvideo と入力します。すると ComfyUI CogVideoX Wrapper があるので、そこの Install をクリックします。インストールが終わったら ComfyUI を再起動します。
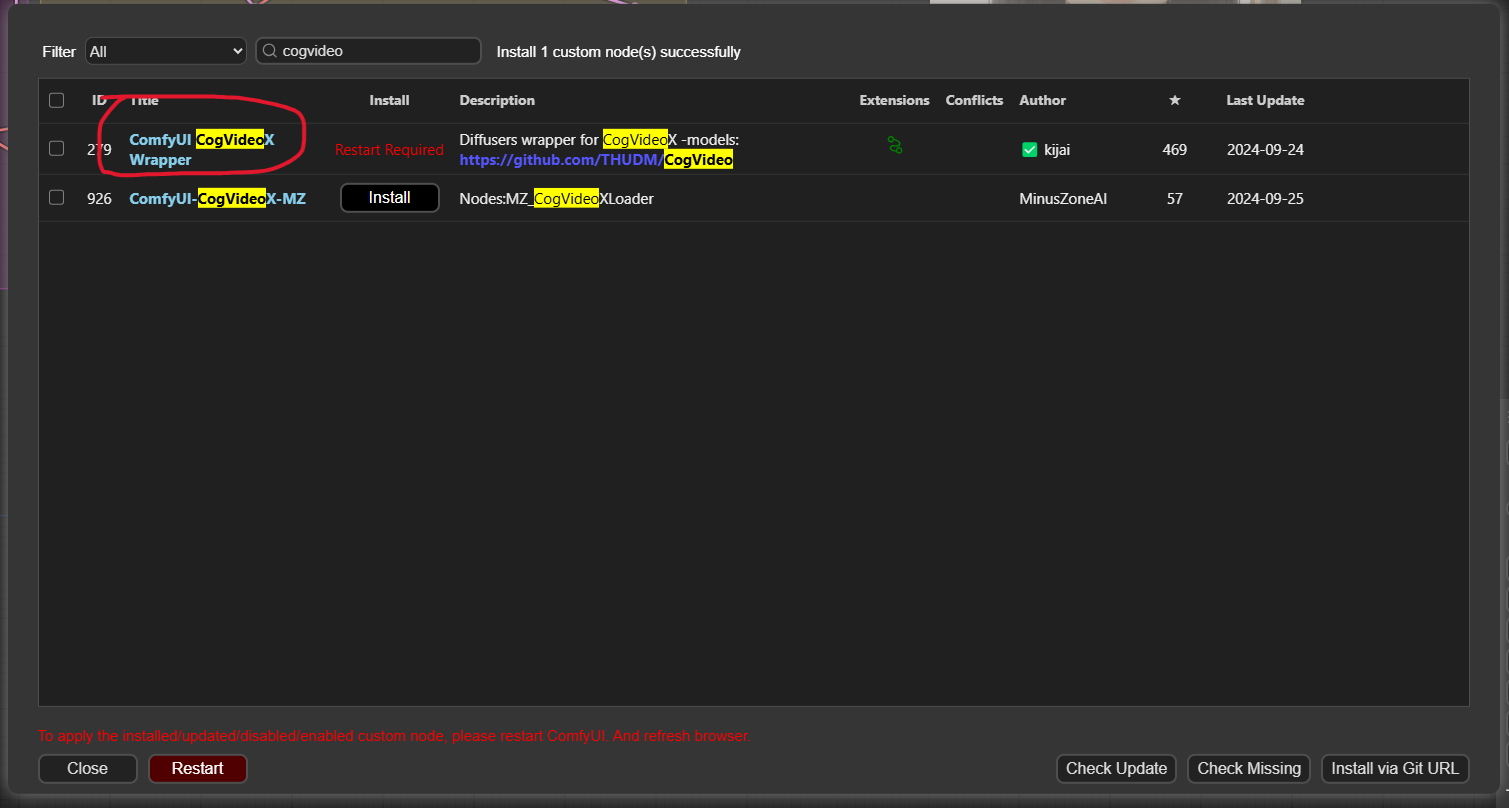
動画を保存するカスタムノード、ComfyUI-VideoHelperSuite (カスタムノード名としては VHS と表記されている場合もあります) もインストールします。
Image2Video を使用する際に、画像のリサイズを行うカスタムノードを使うため、KJNodes for ComfyUI をインストールします。
CogVideoX-Wrapper の Git リポジトリにある ワークフロー例 から、以下 2 つのファイルをダウンロードします。
- cogvideox_5b_example_01.json
- cogvideox_I2V_example_01.json
モデルは生成のときに必要に応じて自動的にダウンロードされますが、ダウンロード済みであれば ComfyUI/models/CogVideo 配下に配置する必要があります。
生成
Text2Video
Text2Video では、以下のワークフローを使います。
- cogvideox_5b_example_01.json
モデルは、CogVideoX-5b か、GGUF モデルを使います。ただ、そのままだとメモリ不足になるので、以下の通り変更します。
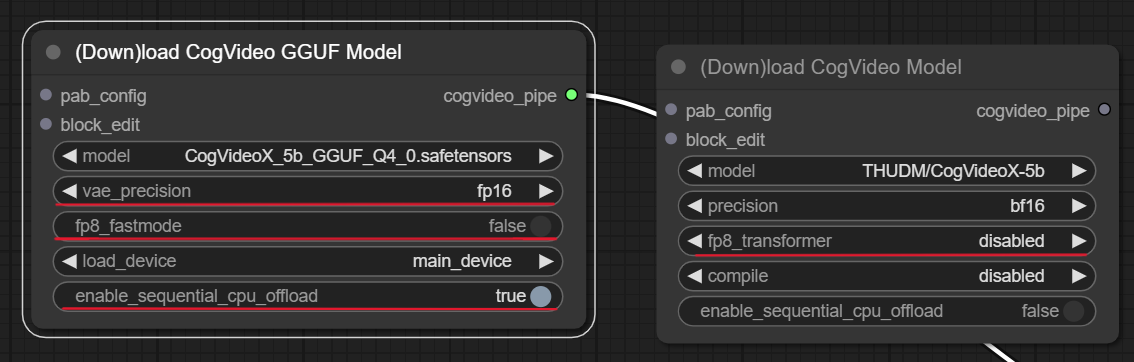
- vae_precision を
fp16 - fp8_fastmode は
falseのまま (RTX40xx などの最新 GPU のみ対応する機能とのこと) - enable_sequential_cpu_offload を
true
GGUF ではないモデルを使用する場合は、fp8_transformer の設定を enable にします。この選択肢に fastmode がありますが、これが GGUF モデルのロードにある fp8_fastmode を true にしたのと同じことになるようです (そのため、fastmode ではなく enable にします)。
もう一か所、CogVideo Decode ノードも設定変更します。
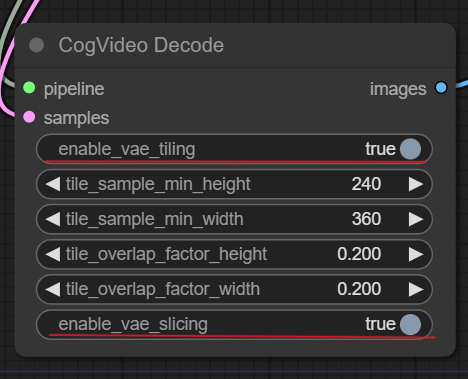
- enable_vae_tiling を
true - enable_vae_slicing を
true
これでプロンプトを入力して生成することができました。
ですが、初期値では step が 50 になっています。これを 30 くらいまで減らしてもそれほどクオリティは下がらず、生成にかかる時間は短縮できるので、以下のように steps を 30 に変更しました。
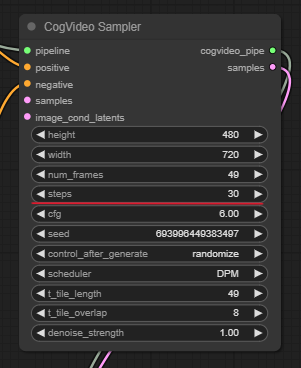
30steps で生成した際のコンソールを見てみると、1552.33 seconds と表示されているので、26分弱。ちょっと試行錯誤する程度ではないですよねぇ
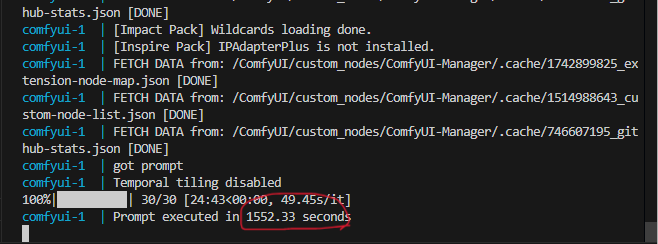
Image2Video
Image2Video では、以下のワークフローを使います。
- cogvideox_I2V_example_01.json
モデルは、CogVideoX-5b-I2V のように、I2V がついているモデルを使用します。その他の設定は、Text2Video と同様に設定しないとやはりメモリ不足になります。
エラー
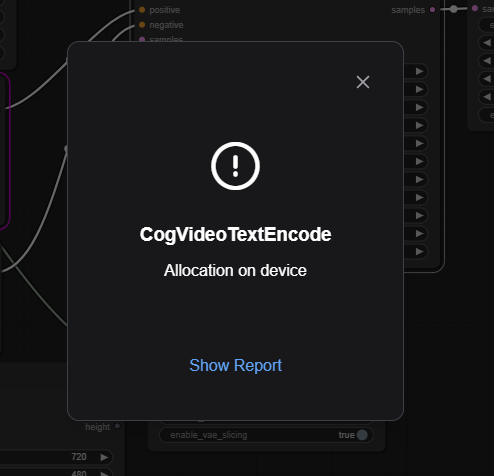
生成中によくエラーになります。上記の設定をしてもエラーになることが度々あります。大体は、再度生成を行えば、何事もなかったかのように処理が進みますが、たまに再実行してもダメなことがあります。その場合は ComfyUI を再起動したりしないとダメなこともありました。
一応生成はできますが、スペック的にはギリギリなんでしょうね。