
Style Bert Vits2
TTS (Text To Speech) で日本語の表現に対応した Style-Bert-VITS2 を試してみました。
概要
- GeForce RTX 2070 (8GB) でも音声合成、および音声データから学習して独自の音声データを作成することもできました
準備
以前の記事で作成した WSL2 の Docker で CUDA する を参考に、GPU を使えるように設定済みのコンテナを使います。
今回も docker compose を使用して環境を整えようと思います。compose.yml ファイルは以下のように記述します。
services:
sbv2:
image: nvcr.io/nvidia/cuda:12.1.0-base-ubuntu22.04
volumes:
- ./Style-Bert-VITS2:/Style-Bert-VITS2
command:
- /bin/bash
- -c
- |
apt update
apt install -y git python3-pip libgl1-mesa-dev libglib2.0-0 ffmpeg
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
cd /Style-Bert-VITS2/
pip install -r requirements.txt
python3 initialize.py
python3 app.py --host=0.0.0.0
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
ports:
- "7860:7860"
- "6006:6006"
WebUI 用に 7860 番と、学習状況の参照のために TensorBoard を開きたいので、6006 番を転送するようにします。
その上で、Style-Bert-VITS2 (以下、SBV2) のリポジトリを以下のようにクローンします。
git clone https://github.com/litagin02/Style-Bert-VITS2.git
この状態で、以下のように compose.yml ファイルとリポジトリをクローンしたディレクトリが配置された状態になっているはずです。SBV2 はダウンロードしたファイルはリポジトリのディレクトリ内に保存しているようだったので、このディレクトリのみコンテナ内と共有すれば環境構築でき、ダウンロードしたモデルなども保管されました。
.
|- Style-Bert-VITS2/
-- compose.yml
起動
ファイル、ディレクトリの準備ができたら、以下のコマンドを実行します。
docker compose up
ComfyUI のように WebUI の URL が表示されたりすることがないため、いつ WebUI にアクセスできるようになるのかがわかりにくいですが、
sbv2-1 | 12-05 13:36:20 | DEBUG | __init__.py:92 | try starting pyopenjtalk worker server
sbv2-1 | 12-05 13:36:20 | DEBUG | __init__.py:130 | pyopenjtalk worker server started
こんな感じで worker server がスタートしていたらおそらく WebUI に接続できるので、ブラウザで http://localhost:7860 にアクセスすると WebUI が開けると思います。
音声合成
WebUI を少し下にスクロールすると、音声合成を行う入力欄があります。
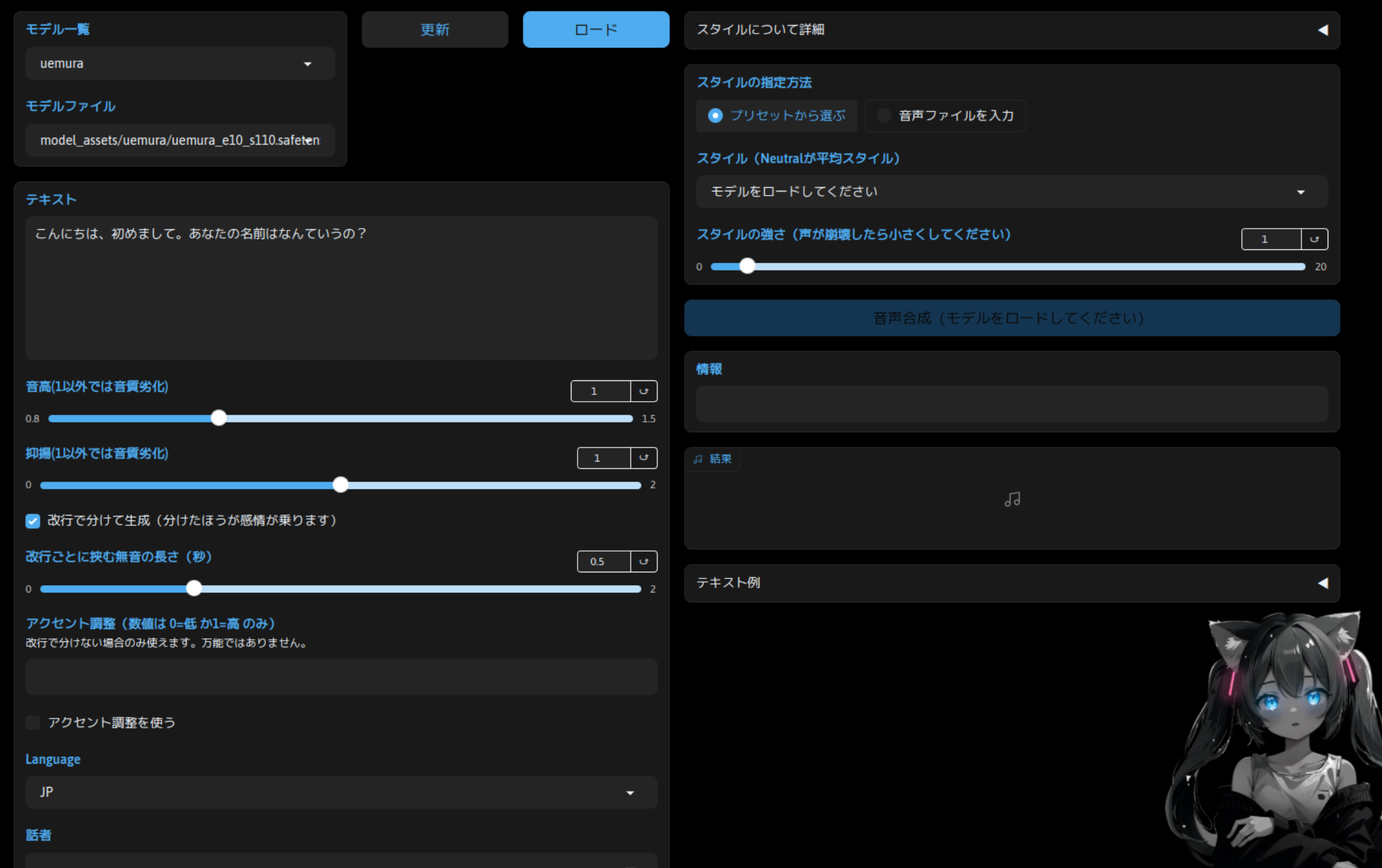
基本的には、「モデル一覧」で任意のモデルを選択し、「ロード」ボタンをクリックしてモデルを読み込みます。「テキスト」に生成したい文章を入力し、「音声合成」ボタンをクリックすれば「結果」欄に表示されます。
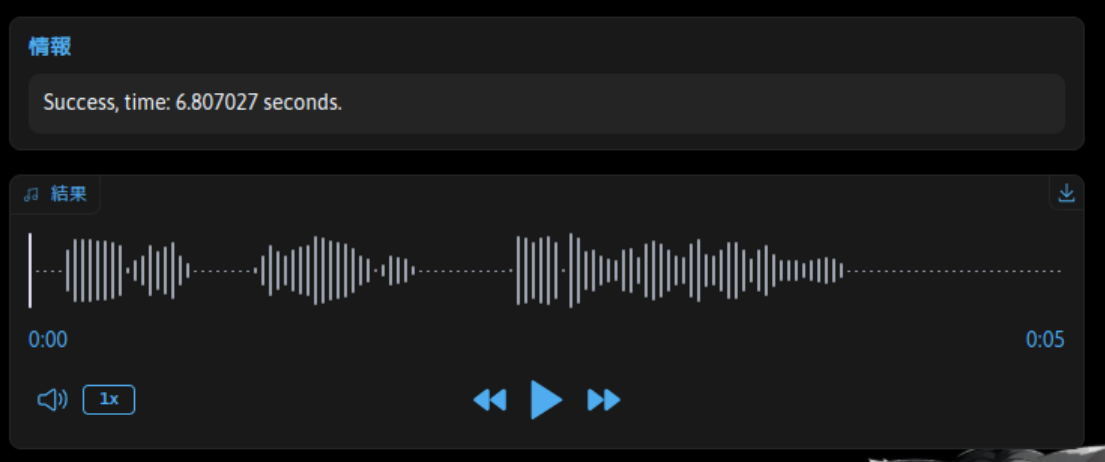
再生ボタンをクリックすればブラウザ上で再生できますし、小さいですが結果欄の右上のダウンロードアイコンをクリックすれば、音声ファイルをダウンロードできます。
学習
学習には GPU が必要です。また、音声データも必要になります。音声データは、テキストを読み上げている音声を2分程度録音したデータを、test.wav というファイル名で用意しました。(MP3 だとうまく処理できなかったので、WAV にして使用しました)
音声データの準備
test.wav を、SBV2 のリポジトリをクローンしたディレクトリの input 直下に配置します。そのうえで、SBV2 の WebUI の「データセット作成」タブを開きます。
※「使い方」を展開すると詳しい説明が表示されます。
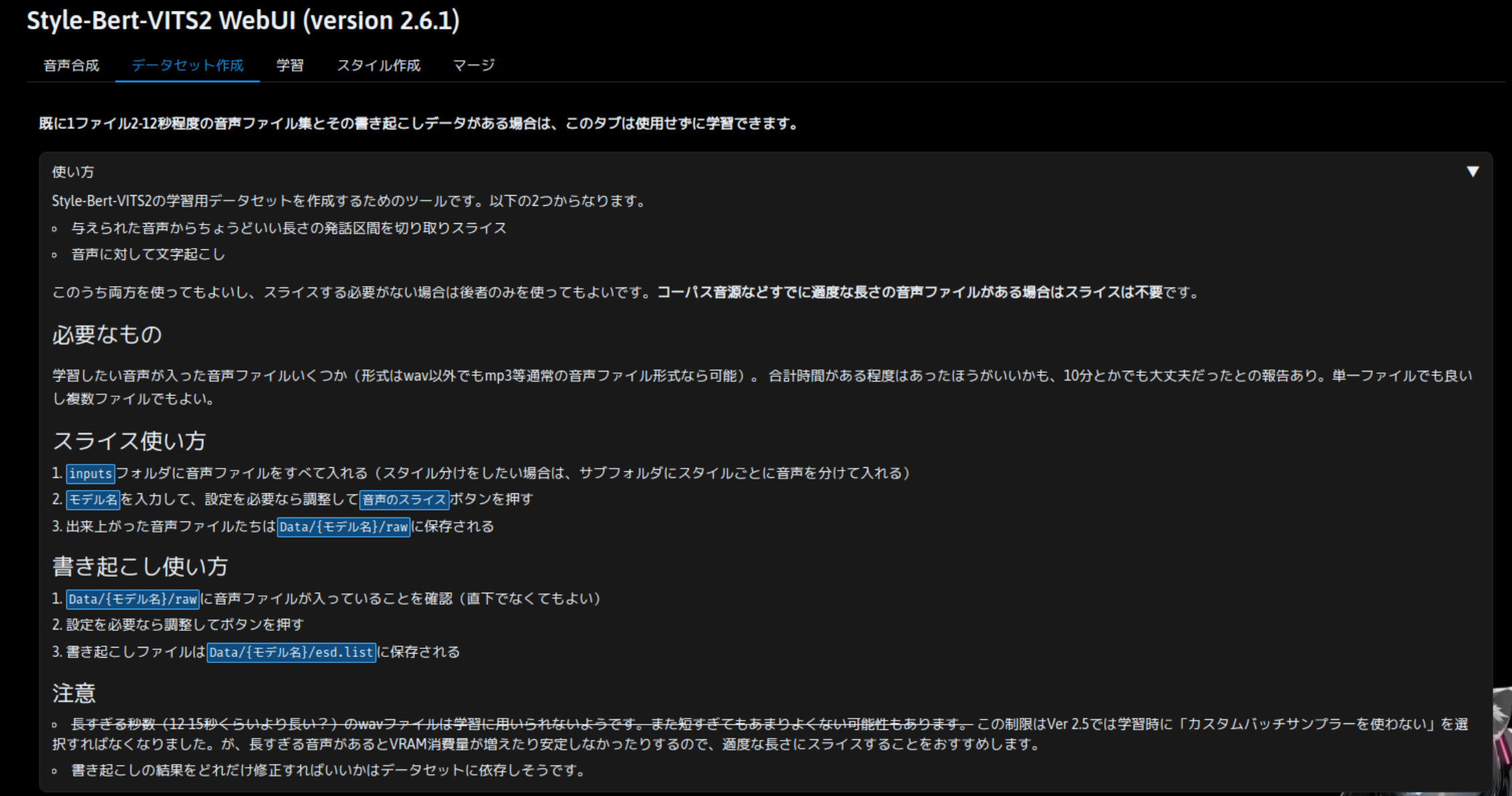
モデル名を入力しますが、今回は test としてみます。
音声データの分割
適度な長さの音声データに分割されている場合は不要ですが、今回のように単一ファイルである程度の長さのデータの場合、分割する必要があります。「音声のスライス」でそれを実施します。
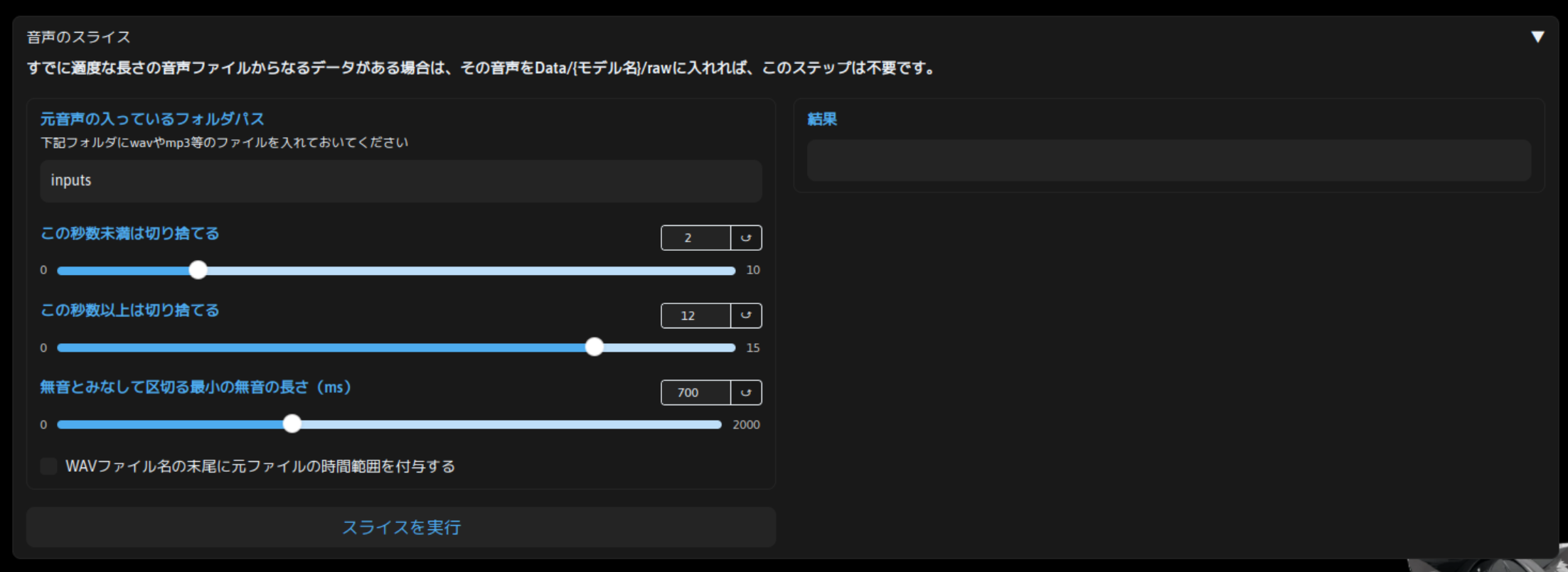
パラメータは特に変更せず、「スライスの実行」をクリックします。「結果」欄に「音声のスライスが完了しました」と表示されれば OK です。

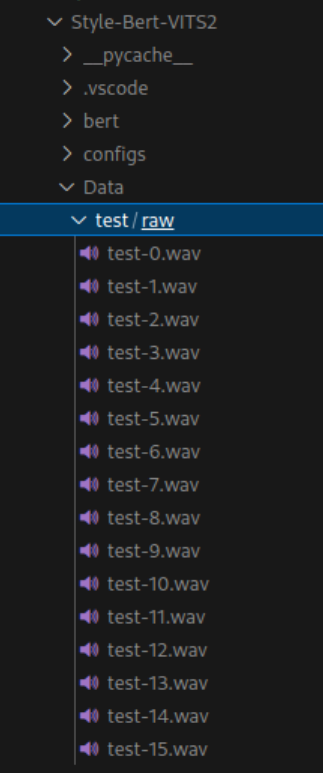
この状態で、Style-Bert-VITS2/Data/ 以下に test/raw というディレクトリが作成され、そこに test.wav が分割された test-x.wav というファイルが作成されます。処理時間は元々のファイルの長さによると思いますが、今回は 5 秒もかからない程度でした。
音声の文字起こし
さらに下へスクロールして、「Whisper モデル」欄で音声データの文字起こしを行います。こちらも基本的にパラメータは初期値のまま、「音声の文字起こし」をクリックします。今回はモデル名に test と入力しているので、Style-Bert-VITS2/Data/test/ 配下のファイルを処理対象として文字起こしを行います。
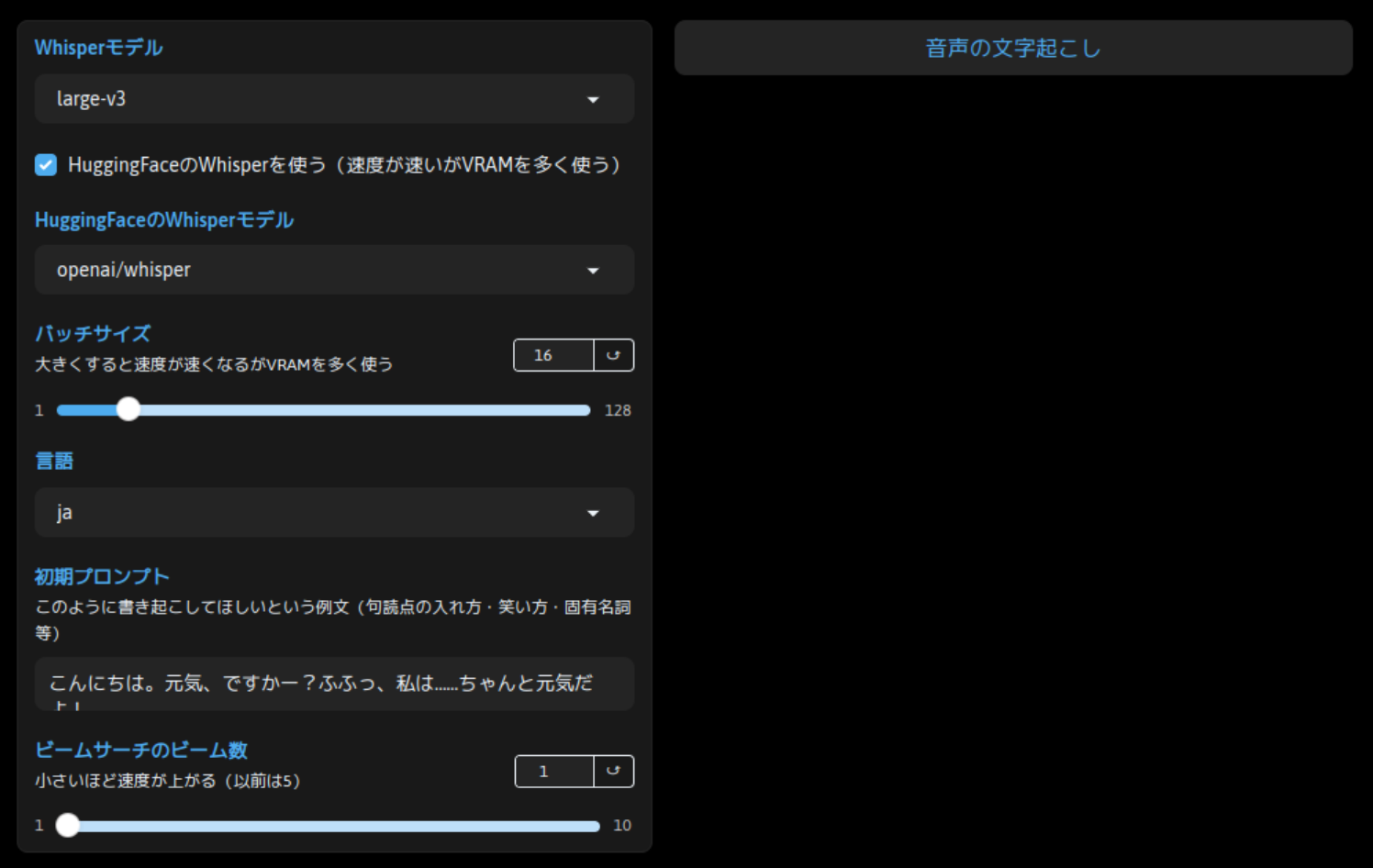
完了すると、「結果」欄に「音声の文字起こしが完了しました。」と表示されます。今回は 100 秒程度かかりました。
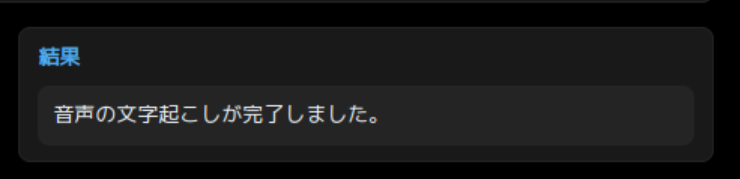
結果として、Style-Bert-VITS2/Data/test/ 配下に esd.list というファイルが作成されます。これは特定のフォーマットに沿って、各音声ファイルの内容にどのようなテキストが含まれているかを記述したファイルになっています。
ファイルは普通のテキストファイルなので、ファイルの形式を崩さない程度に、文字起こしに誤りがあったら修正してもいいかもしれません。
ここまででデータの準備は完了です。
学習実行
音声データの準備が完了したら、引き続き「学習」タブを開きます。こちらも「使い方」を展開すると細かい説明がありますが、「データセット作成」タブでデータを準備した場合はそのまま作業できます。データセット作成タブを使わずに、独自にデータを用意した場合は、「使い方」の内容を見てデータを正しく配置する必要があります。
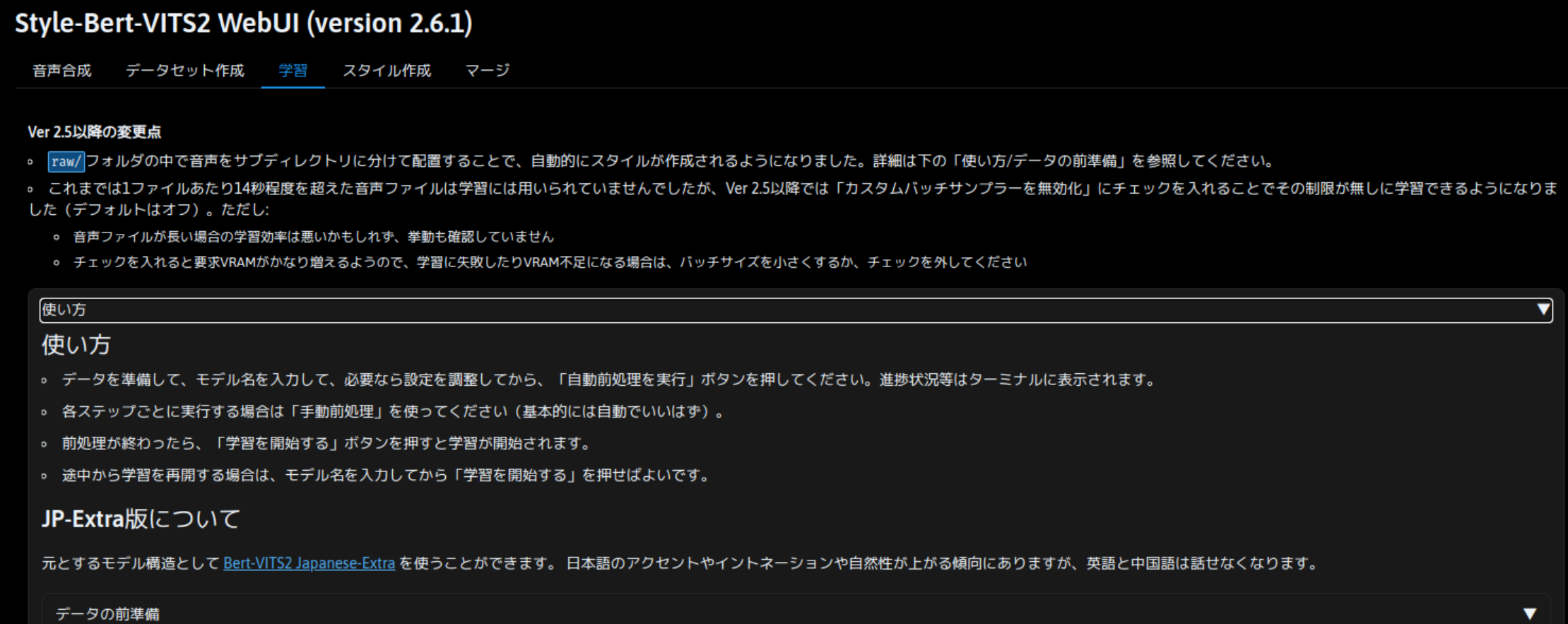
自動前処理
学習を行う際のパラメータを準備します。まずモデル名は「test」と入力します。これで Style-Bert-VITS2/Data/test/ 配下のデータを使用するようにできます。
また、「自動前処理」項のパラメータは初期値のまま実行してみました。学習した結果として、精度が良くなかった場合はこの辺の調整して学習し直すことで、改善を図れるかもしれませんが、一旦は初期値で実行してみます。
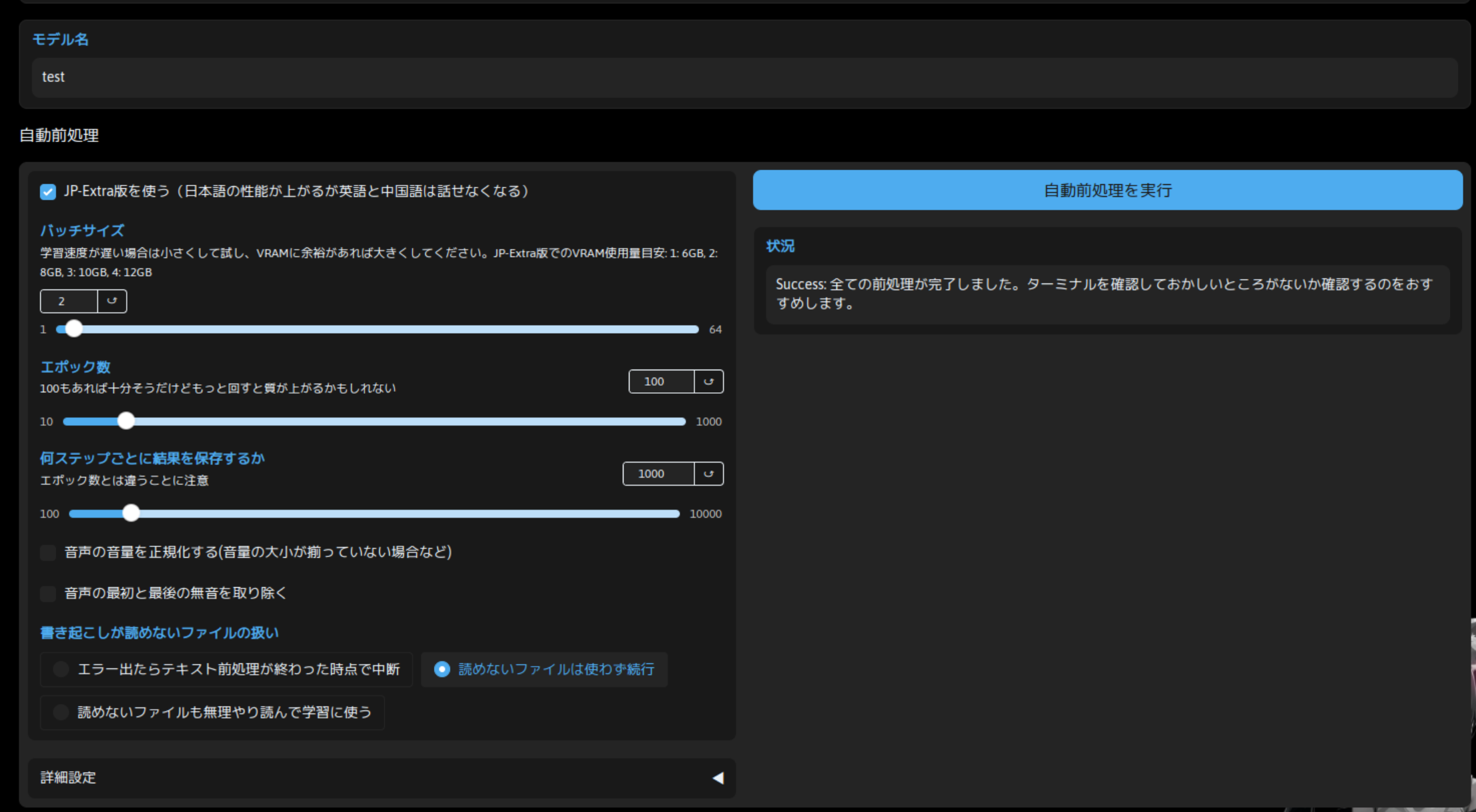
これで「自動前処理を実行」ボタンをクリックします。30 秒程度で処理が完了すると思います。
結果として Style-Bert-VITS2/Data/test/ 配下にさまざまなファイルが出力されますが、config.json などの学習に必要なパラメータを記述したファイルが出力されていることが確認できます。
学習
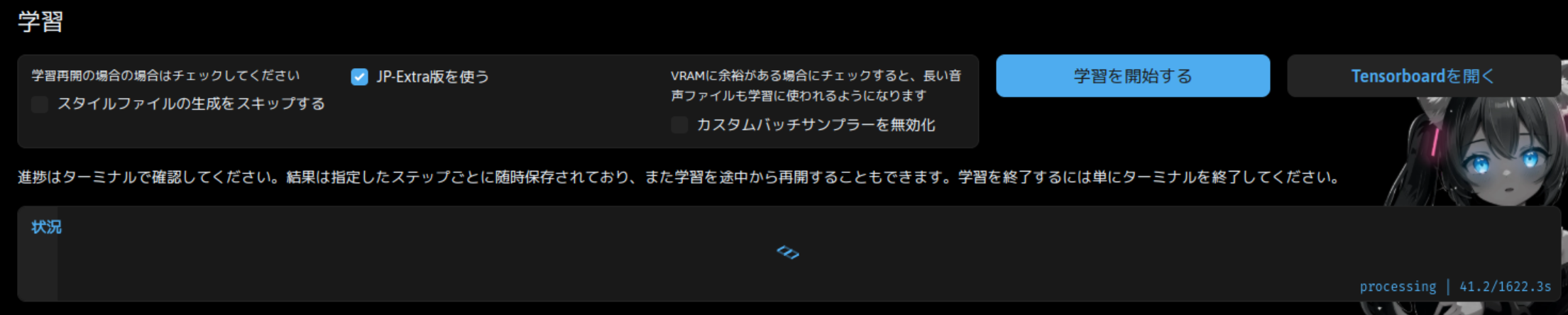
準備はできたので、あとは「学習を開始する」をクリックするだけです。それなりに時間はかかりますが、特定のステップごとに結果を保存しているので、中断しても最初から、では無いと思います。

その下の「状況」欄に進捗が表示されます。
学習が完了すると、学習が完了しましたと表示されます。今回は 20 分程度の時間が必要となりました。
学習した音声で生成
「音声合成」タブを開き、モデル一覧で「test」を選択すると、学習したモデルで合成した音声を生成できます。結構元の音声データを作成したときの雰囲気を再現して合成できている点に驚きますが、少し不明瞭に感じる部分があるので、そういうところを改善していく方法は、今後の課題かと思います。