
ComfyUI で Stable Diffusion 3.5 Large/Large Turbo を試してみる
StabilityAI より、Stable Diffusion 3.5 のご紹介 という記事が公開されていました。Stable Diffusion 3.5 Large と Stable Diffusion 3.5 Large Turbo はモデルのダウンロードが可能で、無料で利用可能。Stable Diffusion 3.5 Medium は 2024/10/29 に公開予定とのこと。まずは Stable Diffusion 3.5 Large と Stable Diffusion 3.5 Large Turbo を試してみます。
概要
- ComfyUI で生成できました
- GeForce RTX 2070 (VRAM 8GB) でも生成できました
- Stable Diffusion 3.5 Large は 1 回生成するのにおよそ 6 分間程度、Stable Diffusion 3.5 Large Turbo は 30 秒程度かかります
準備
モデルをダウンロードします。Hugging Face で公開されていますが、利用規約への同意が必要です。
Stable Diffusion 3.5 Large の場合は、以下 2 ファイルをダウンロードします。テキストエンコーダは、SD3 や Flux.1 で使用したものが使えました。それらがない場合はダウンロードしておきます。
Hugging Face: https://huggingface.co/stabilityai/stable-diffusion-3.5-large
- sd3.5_large.safetensors
- SD3.5L_example_workflow.json
Stable Diffusion 3.5 Large Turbo の場合は、以下のファイルをダウンロードします。
Hugging Face: https://huggingface.co/spaces/stabilityai/stable-diffusion-3.5-large-turbo
- sd3.5_large_turbo.safetensors
- SD3.5L_Turbo_example_workflow.json
モデル (拡張子 .safetensors) は ComfyUI/models/checkpoint/ 以下へ、ワークフローは WebUI を使用する端末に保存します。
生成
ComfyUI を docker compose で構築する で用意した docker compose を使います。もしコンテナを起動していない場合は、docker compose start などで起動し、WebUI にアクセスできるようにします。
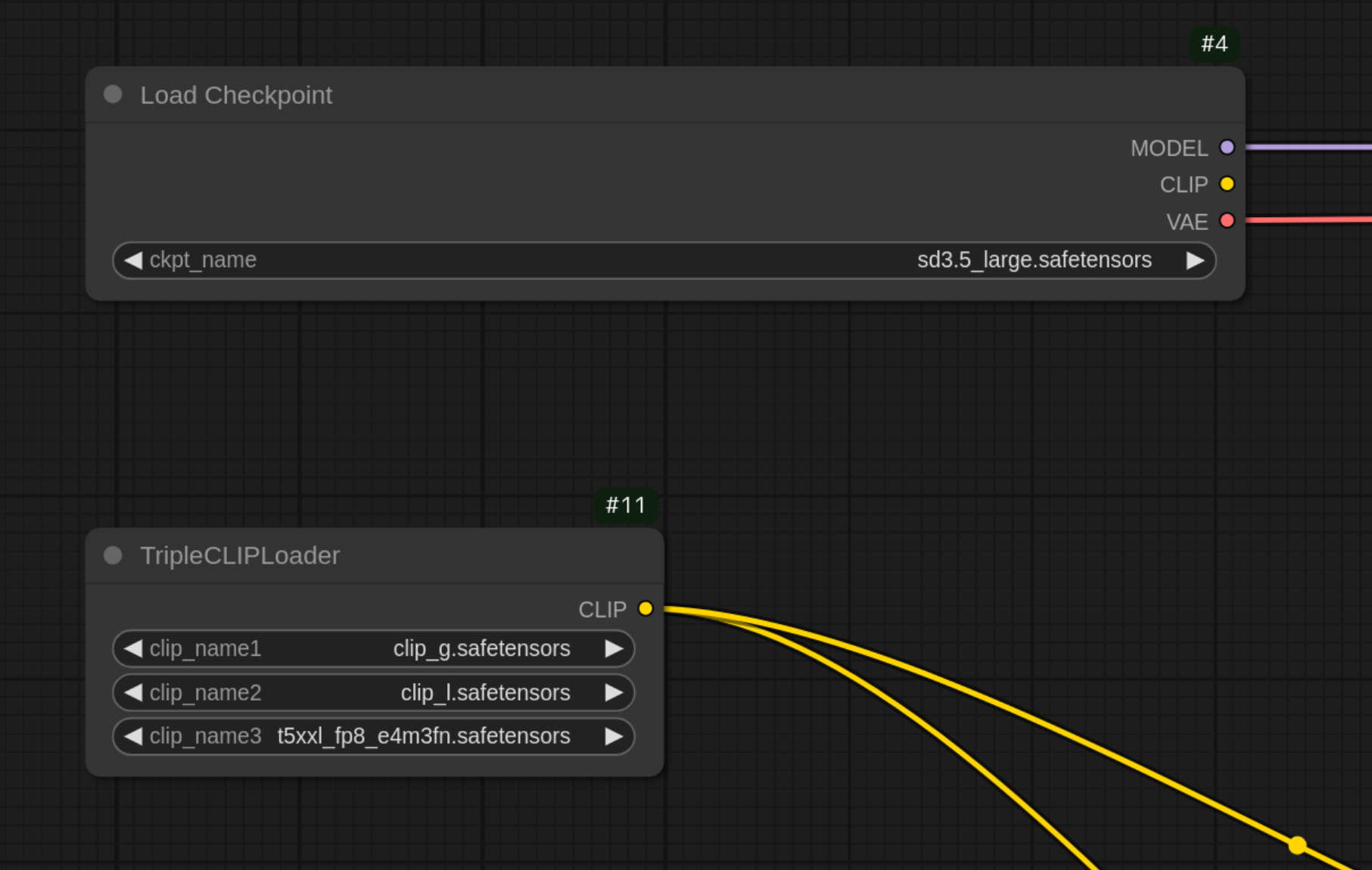
ワークフローを読み込ませます。Load Checkpoint と TripleCLIPLoader でモデルが正しく指定されていることを確認します。TripleCLIPLoader は、Flux.1 等で使用したものとはファイル名が異なる場合があるので、クリックしてローカルにあるファイル名に選択し直します。
あとはいつもどおりプロンプトを入力して Queue Prompt すれば生成されます。
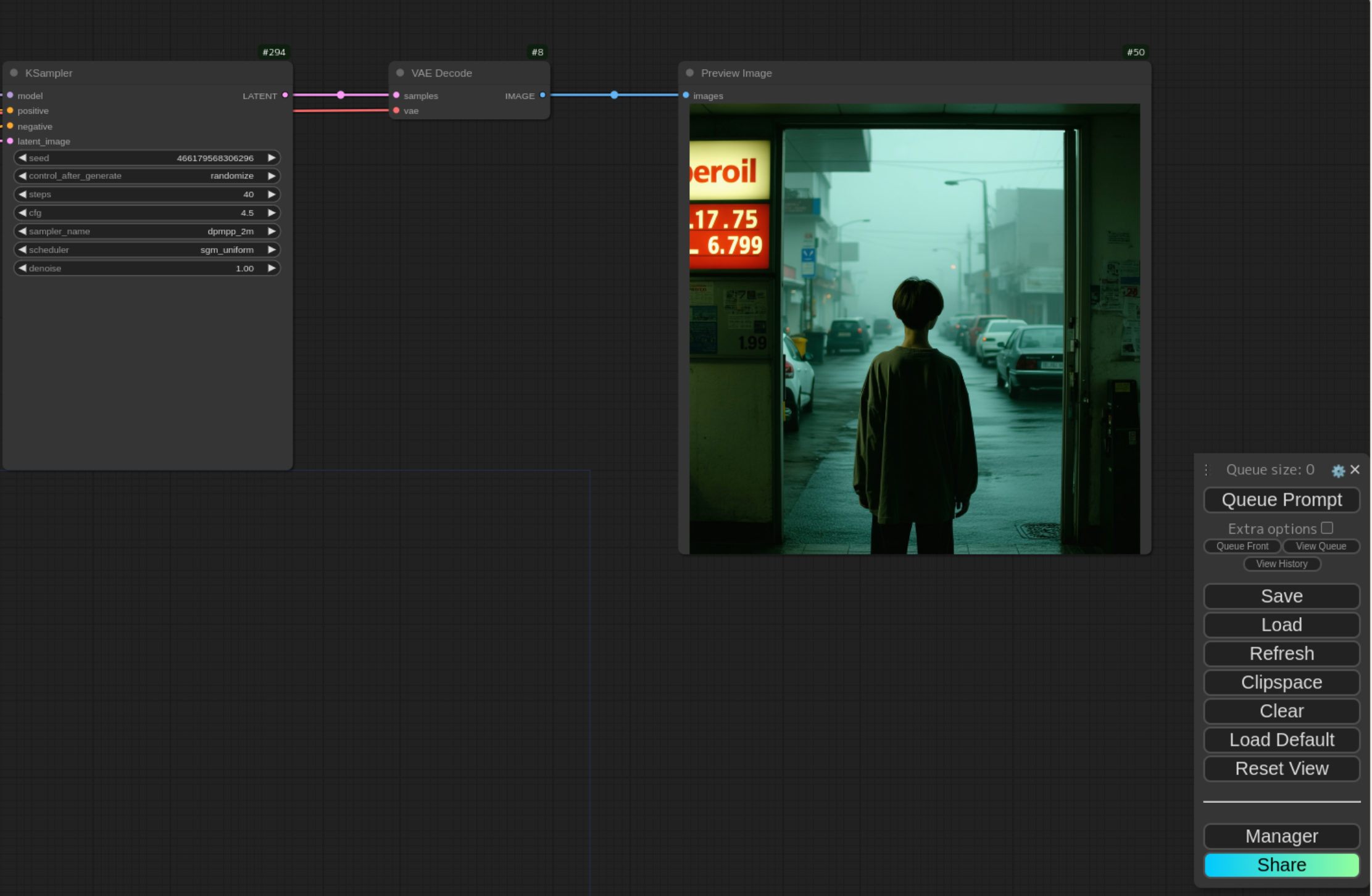
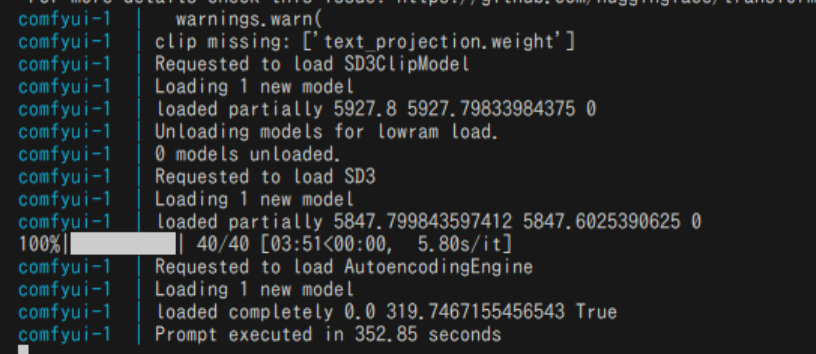
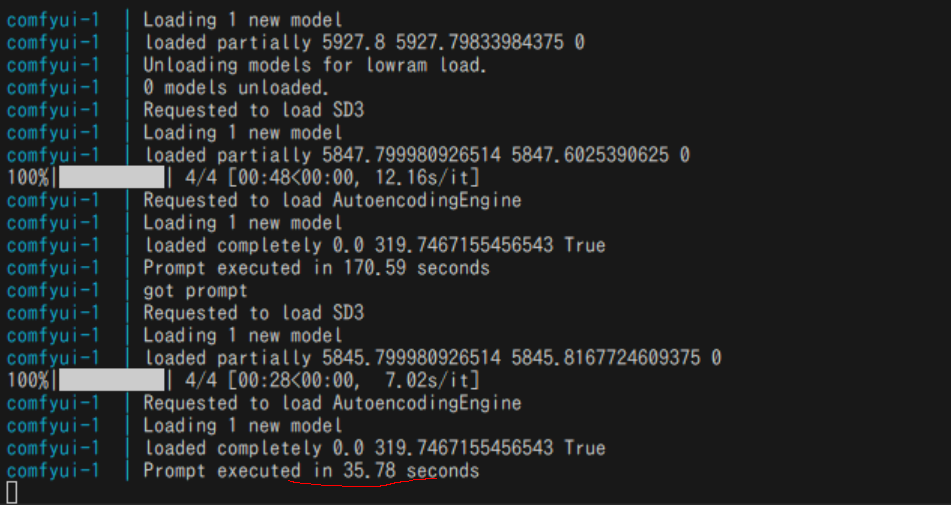
生成にかかる時間は以下の通り 352.85 秒。
Stable Diffusion 3.5 Large Turbo も、ワークフローを読み込ませてモデルを適切に設定すれば生成されます。
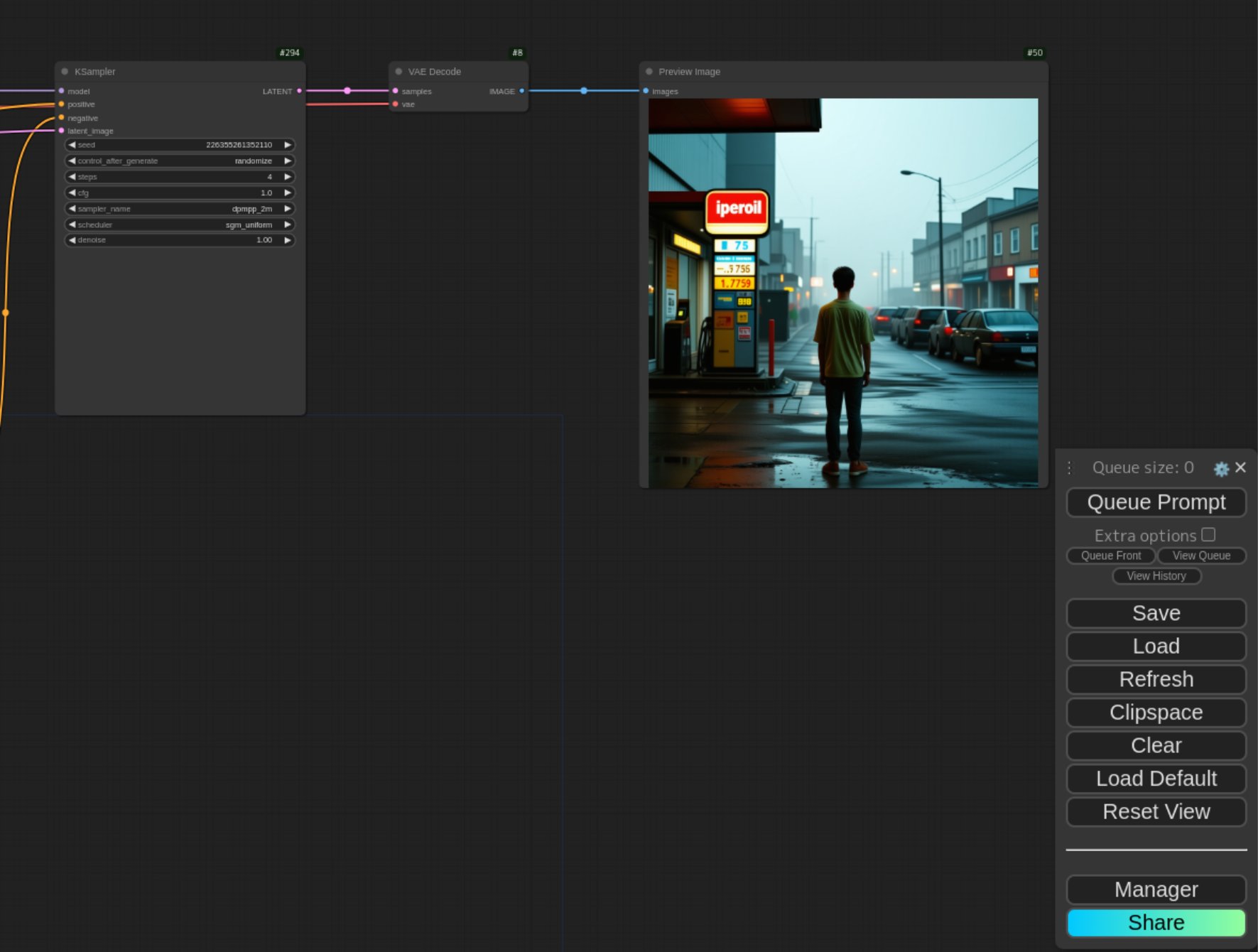
Turbo は 4steps なので、生成にかかる時間は短くなります。以下の通り 35.78 秒と、40steps で生成している Turbo ではない方のちょうど 1/10 になっていますね。ただ、それでも 30 秒以上かかるので、RTX 2070 には荷が重いのかもしれません。
備考
冒頭に「GeForce RTX 2070 (VRAM 8GB) でも生成できました」と記載しましたが、Stable Diffusion 3 や Flux.1 と比べても負荷が高いのかもしれませんね。普段は同時に OpenWebUI を起動して、プロンプトを生成 > ComfyUI で画像を生成 > 修正したい箇所を OpenWebUI で調整してプロンプトを再生成 > ComfyUI で画像を生成、のようにしてたのですが、Stable Diffusion 3.5 で画像を生成すると OpenWebUI が内部エラーで停止してしまいます。逆に OpenWebUI を実行してから ComfyUI で Stable Diffusion 3.5 の画像生成をしようとするとエラーになるので、現時点では併用できない状態です。